



The insider field guide to who the modern data scientist really is in 2026, what they actually earn, where they cluster, and how to recruit and screen them without getting fooled.
Mark Zuckerberg told colleagues that for a company spending hundreds of billions on compute, it is worth doing whatever it takes to sign the top 50 to 70 AI researchers on the planet - Fortune. That sentence is the whole market in miniature. The people you are trying to hire when you say "data scientist" in 2026 are no longer a commodity role you post and fill. At the very top, the pool of people who can lead the training of a frontier model is estimated at fewer than 1,000 worldwide - Fortune. At every level below that, the same forces have pulled the role apart and repriced it.
The problem is that almost everyone still hires for this person using a 2018 mental model. They write a job description for a "data scientist," screen with a LeetCode round, and wonder why the good ones never reply or never pass. The role that used to mean one person building dashboards and regression models has fractured into at least five distinct jobs with different skills, different status games, and pay that spans an order of magnitude for the same nominal title. Recruiting this group well is less about posting a req and more about understanding a species: where it evolved from, what it values, and which signals actually separate the person who can ship from the person who can only talk.
This guide is the practical map of that species, written for someone who has to act on it rather than skim headlines. It covers what the modern data scientist actually became, the five tribes hiding under one title, how many of them exist and why so few can do the real work, what each tier genuinely earns, where they physically live, the channels and signals that find them, what makes them move and stay, how to screen each tribe without being fooled by an AI-assisted candidate, the sourcing playbook and tooling, the parts the recruiting market never advertises, and where AI agents take all of this next.
This guide is written by Yuma Heymans (@yumahey), founder of HeroHunt.ai and a former Bain and KPMG consultant. He spends his days on exactly the problem at the center of this market, finding scarce technical specialists who are not on any job board, which is why he writes about how the labs and the smartest in-house teams actually do it.
Contents
- The Data Scientist Did Not Die, It Split Into the AI Engineer
- The Five Tribes Hiding Under One Job Title
- The Numbers: How Many Exist and Why So Few Can Do the Real Work
- What They Really Earn: The Whole Ladder, Not the Headlines
- Where They Actually Live
- Where to Find Them: The Signals That Predict Ability
- What Makes Them Move, and What Makes Them Stay
- How to Screen Them Without Getting Fooled
- The Sourcing Playbook and the Tool Stack
- The Insider Reality Nobody Advertises
- The Future: When AI Agents Recruit and Build AI Engineers
1. The Data Scientist Did Not Die, It Split Into the AI Engineer
The single most useful thing to understand before you recruit a single person is that "data scientist" in 2026 is a legacy umbrella term that describes a job most of the people you actually want no longer do. The title was coined around 2008 for a generalist who could query data, build a model, and explain a result to the business. That generalist still exists, but the center of gravity, the money, and the demand have moved decisively toward people who build and deploy machine learning systems on top of large pre-trained models. When a hiring manager says "we need data scientists," nine times out of ten what they mean, and what the market will charge them for, is some flavor of machine learning or AI engineer.
The clearest evidence of the shift is in the language of the market itself. Stanford's AI Index found that in 2024, for the first time since tracking began in 2010, the skill cluster "artificial intelligence" overtook "machine learning" as the single most-requested AI competency, while US postings naming generative AI jumped to 66,000 from 16,000 in a single year - Stanford HAI. The role that absorbed this demand has a name. In a June 2023 essay that now reads as a forecast, the writer swyx (Shawn Wang) defined the AI engineer as a software engineer who ships products on top of foundation models rather than training them, noting there were then ten times as many machine learning engineer jobs as AI engineer jobs and predicting the ratio would invert within five years - Latent Space. Two and a half years later, AI Engineer was the number one fastest-growing job in the United States on LinkedIn's list, two years running - Dice.
The deeper change underneath the titles is what the job feels like to do, and it reframes who you should even be looking for. Andrej Karpathy, a founding member of OpenAI, captured it in his 2025 keynote arguing that software is being rewritten a third time: hand-written code, then neural-network weights, and now natural-language prompts as a kind of programming, with the engineer's job shifting from writing every line to steering partially autonomous agents - Latent Space. For a recruiter, this is not philosophy. It means the candidate who can orchestrate models, design evaluations, and verify agent output is now more valuable than the candidate whose entire identity is hand-tuning a gradient-boosted tree. The talk below is the single best primer on why the skill profile you are hiring for has changed underneath you.
Andrej Karpathy: Software Is Changing (Again)
None of this means the classic data scientist is unemployable, and treating the change as a simple death is a recruiting mistake in the other direction. Indeed's data shows data scientist postings actually rose around 15% over three years and were a rare bright spot while overall tech postings sat well below their 2022 peak, with only a tiny share of tech layoffs touching data-science roles - Research.com. What changed is not that the role vanished but that it stratified by how close the work sits to shipping a model. The market now quietly sorts the title into successors with a clear pay gradient, with reported median total compensation of roughly $140K for a data scientist rising to about $185K for an AI engineer - Pin. Your first recruiting decision, before you write a word of a job description, is to figure out which successor you actually need, which is the subject of the next section.
2. The Five Tribes Hiding Under One Job Title
The most expensive mistake in this market is treating the people under the "data scientist" or "AI" banner as interchangeable, because they are at least five different tribes that share a screen and almost nothing else. They went to different schools of thought, they prove themselves in different ways, they want different things, and they fail spectacularly in each other's jobs. A brilliant research scientist will often be a mediocre product engineer, and a world-class AI engineer may have never trained a model from scratch in their life. Before you can source or screen anyone, you have to know which animal you are hunting, because the channel and the test that work for one are wasteful or actively misleading for another.
The split runs along a single axis: how close the work sits to inventing new model capability versus shipping a working product. The diagram below maps the family tree, and it is worth internalizing before you read any job description, your own included.
At the top sits the research scientist, the person who defines what to research and pushes the frontier of what models can do. This tribe is genuinely PhD-gated, judged on published papers, and rare to the point that acceptance rates at the top labs run below half a percent - Sundeep Teki. Beside them, and often confused with them, is the research engineer or machine learning engineer, who makes the ideas work at scale: profiling training runs, implementing a novel attention mechanism, and debugging the data pipeline that feeds a billion-parameter model. The distinction matters because labs hire and pay them on separate ladders. A third tribe, the applied scientist, is largely Amazon's name for what others call a research scientist, except that an applied scientist must clear an engineering coding bar and spends real time optimizing latency in production rather than only writing papers - Eugene Yan.
The two remaining tribes are where most of the volume hiring now happens, and they are the ones most teams under-respect. The AI engineer is the foundation-model application builder, the software engineer who composes products out of model APIs, retrieval pipelines, agents, and evaluation harnesses, and who, in swyx's blunt phrasing, needs no PhD because "when it comes to shipping AI products, you want engineers, not researchers" - Latent Space. The data engineer and its analytics-engineer cousin own the pipelines and infrastructure that everything else depends on, the least glamorous and most chronically under-hired of the five. The practical lesson is that "we need a data scientist" is never a real requirement. The real requirement is one of these five, and the entire rest of this guide changes depending on which.
Getting the tribe wrong is not a minor labeling error, it cascades into wasted budget and failed hires. Recruit a research scientist when you needed an AI engineer and you will pay a seven-figure package for someone who wants to write papers, not ship your chatbot, and who will leave the moment a lab offers them a real research agenda. Recruit an AI engineer when you needed a research scientist and you will get a beautifully engineered product wrapped around a model nobody on the team can actually improve. The frontier labs themselves keep these ladders deliberately distinct, with OpenAI titling much of its technical staff as Member of Technical Staff while still separating research from engineering tracks, and Anthropic running a famously flat structure that prizes engineers who think like researchers - Data Exec. Map your need to the tribe first, and everything downstream, the sourcing channel, the screen, the pitch, and the price, falls into place.
A sixth title is now rising fast enough to deserve its own mention, the Forward-Deployed Engineer, borrowed from Palantir and adopted by OpenAI, Anthropic, and Google to put technical people directly in front of enterprise customers. It is a hybrid of the AI engineer and a customer-facing solutions role, and demand has exploded, with postings up more than fiftyfold against early 2025 and frontier-lab packages reaching past $500,000 at senior level against a broad-market median nearer $174,000 - MindStudio. For a recruiter, the FDE is worth knowing because it is where product engineering meets deployment, and the people who do it well combine the AI engineer's model fluency with a consultant's ability to translate a messy enterprise problem into something a model can actually solve, which is a rarer blend than either skill alone. If you are hiring for adoption rather than for raw model capability, this is increasingly the tribe you want, and it is one most job descriptions still fail to name.
3. The Numbers: How Many Exist and Why So Few Can Do the Real Work
The hard truth that should shape every recruiting budget is that genuine supply is far smaller than the job-posting frenzy implies, and it is most brutally constrained exactly where the demand is hottest. The headline demand numbers are real: LinkedIn data presented at Davos shows AI added roughly 1.3 million new roles to the global economy over about two years, with AI Engineer the single fastest-growing title - World Economic Forum. But job postings are not people. ManpowerGroup's 2026 survey found that 72% of employers still cannot find the AI and digital talent they need, a structural shortage rather than a passing squeeze - HRTech Edge. The result shows up in time-to-fill, which has climbed toward 68 days on average for AI roles and stretches to six or seven months for specialized senior positions.
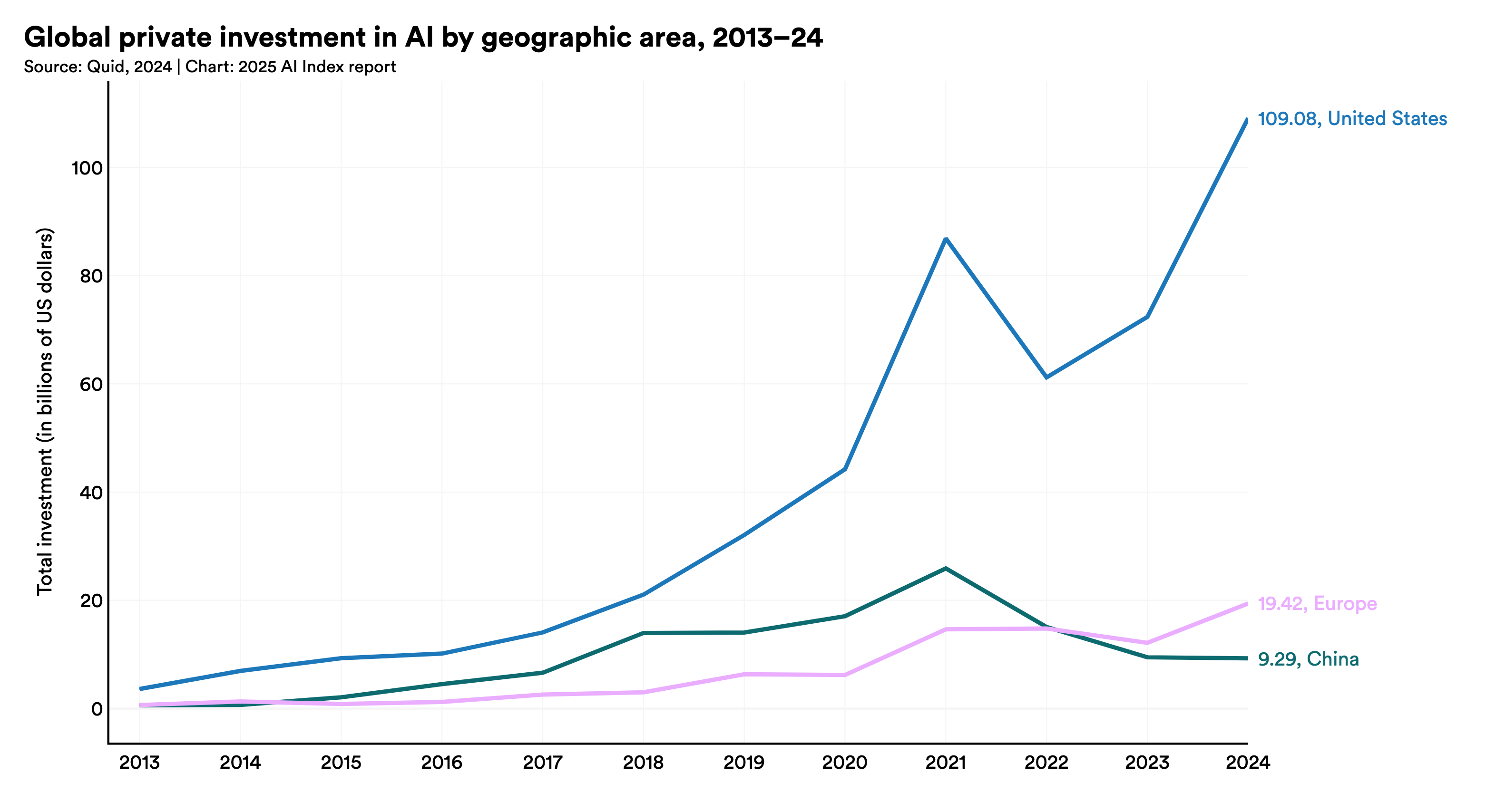
The scarcity is fractal: the closer the role sits to the frontier, the smaller the pool gets, until it becomes almost absurdly tiny. The same WEF data that counts AI jobs in the millions sits on top of a frontier-research pool that Fortune put at fewer than a thousand people qualified to build today's most advanced models. That is why Zuckerberg framed his recruiting target as the top fifty to seventy researchers and built Meta's core lab around roughly fifty people. The macro driver underneath this concentration is capital, which is itself wildly concentrated. The chart below, from Stanford's AI Index, shows why the bidding for these few people is so violent: private AI investment has lopsidedly pooled in the United States, and money at that scale chases a fixed, small supply of the people who can deploy it.
Behind that investment gap sits the supply pipeline, and the pipeline tells a story of demand pulling people out of academia faster than universities can replace them. Stanford's AI Index, drawing on the Taulbee survey, found that 62.75% of new North American AI PhDs went into industry in 2024, with academia's share shrinking, even as the absolute number of new AI PhDs grew 22% over two years - Stanford HAI. In plain terms, the schools that produce frontier talent are graduating more of it, and industry is hoovering up nearly two-thirds of each class. For a recruiter, that means the traditional pipeline of poaching from academia is real but thin and fiercely contested, and the supply growth, while positive, is nowhere near the pace of demand.
One more structural feature of the supply belongs in any honest accounting: it is narrow demographically, which is both a fairness problem and a sourcing opportunity. Across the AI workforce, only about 22% is female by Deloitte's count, only around 12% of AI researchers globally are women, and women hold roughly 16% of AI tenure-track faculty roles - Interface. A recruiter who treats this purely as a diversity checkbox misses the strategic point: an entire under-tapped segment of qualified talent exists precisely because the default channels and the default screens select against it. The teams that build deliberate pipelines into that segment are not just being equitable, they are fishing in water their competitors ignore, which in a market this supply-constrained is a genuine edge rather than a nicety.
Looking two or three years out, the supply question becomes a geopolitical one, because the pipeline that feeds the United States increasingly originates abroad and is no longer guaranteed to arrive. The country has historically retained the overwhelming majority of the China-trained researchers it attracts, with one analysis finding 87 of 100 Chinese-origin researchers who were in the US in 2019 still there in 2025 - Carnegie Endowment. But China is now building a credible domestic frontier base that keeps more of its own talent home, with the large majority of the authors on the DeepSeek papers sitting at Chinese institutions and more than half having no overseas experience at all - Rest of World. For a recruiter planning ahead, the implication is that the imported-talent advantage the US has leaned on is quietly narrowing, and the teams that build relationships with this talent early, before visa friction or a competing domestic offer closes the window, will hold a meaningful edge over the ones that wait.
4. What They Really Earn: The Whole Ladder, Not the Headlines
The defining feature of AI compensation in 2026 is that it is bimodal, and confusing the two modes is how companies either overpay wildly or lose every candidate they want. The headlines describe a tiny frontier where individual researchers are paid like franchise athletes. The reality for the other 99% of hiring is a competitive but comprehensible market where an excellent engineer costs somewhere between two and four hundred thousand dollars. Both are true at once, and the entire discipline of pricing an offer is knowing which mode your specific candidate lives in before you name a number. The chart below shows the two worlds on one axis, and the gap between them is the whole story.
The Bimodal Pay Ladder for AI/ML Talent in 2026 (median total comp)
The lower mode, where almost everyone reading this actually hires, is well-mapped and stable enough to plan around. Levels.fyi data put the median AI-focused software engineer around $245,000 in 2025, with a premium over non-AI peers that widens with seniority, from about 6% at entry level to nearly 19% at the staff level - Levels.fyi. Enterprise machine learning engineers cluster in the $170,000 to $245,000 range, AI engineers a touch higher, and the spread is driven mostly by company tier and location rather than by anything exotic. The practical takeaway is that for the overwhelming majority of roles, you are competing in a market with knowable comparables, and the way you win is rarely by topping the cash number. It is by moving faster, telling a better story, and not fumbling the close.
It helps to hold the tiers in your head as concrete bands, because they price almost mechanically by employer type. The AI labs pay senior individual contributors roughly $500,000 to $900,000 and staff-level engineers $800,000 to well over a million, while the FAANG tier pays the same levels closer to $350,000 to $900,000, and a funded Series B to D startup typically offers a $180,000 to $280,000 base plus equity whose value is a genuine gamble - TechInterview. The lever that matters most in this lower mode is rarely the base, it is the equity structure and the vesting, because a startup that cannot match a lab's cash can still win by offering meaningful ownership, faster vesting, or a real path to liquidity, which is precisely the dimension the labs themselves started competing on once the war heated up.
One more nuance separates the disciplined buyer from the panicked one: this comp is volatile, so anchoring to a single month's headline is a mistake. Levels.fyi data shows the median AI engineer package swinging from a peak near $295,000 in early 2024 down to about $228,000 a year later before recovering toward the mid-$260,000s, a wide band driven by market sentiment as much as by any change in the work itself - Levels.fyi. The practical move is to benchmark against a rolling range rather than a peak, refresh your bands every quarter, and resist the urge to either lowball off a trough or overpay off a spike, because the candidates are watching the same charts you are and will notice which one you anchored to.
The upper mode is a different planet, and it is the one the press obsesses over. At the frontier labs, software engineer median total compensation reaches roughly $710,000 at Anthropic and $805,000 at OpenAI, with research scientists higher still and stock making up the bulk of every package - Levels.fyi. OpenAI's research scientists carry a median near a million dollars a year, with senior levels reported close to $1.5 million. The image below shows just how far the top labs out-pay everyone else for the same job title, with OpenAI sitting in a category of its own.

Then there is the stratosphere, the numbers that broke containment and distorted everyone's expectations, which you must understand precisely so you can talk a candidate down from them. The famous figure is the $100 million signing bonus, a phrase that traces to Sam Altman describing Meta's offers to OpenAI staff on a podcast - CNBC. The framing is disputed: Meta's own executives pushed back, one poached researcher called the sign-on figure "fake news," and the truth is that these were multi-year, mostly-equity packages reserved for a handful of senior leaders, not cash handed over at signing. What is genuinely documented is that Meta lured former Apple foundation-models lead Ruoming Pang with a package reported above $200 million over several years - Entrepreneur, and reportedly dangled a roughly $1.5 billion offer at a Thinking Machines co-founder, which was declined.
The crucial discipline for a recruiter is to read these stratosphere numbers correctly, because candidates increasingly anchor on them. Every eye-watering figure, the $250 million reportedly offered to a 24-year-old, the $1.5 billion offer, is a multi-year package value, not an annual salary, and is overwhelmingly stock that vests over four to six years on conditions the recipient may never fully meet - CNBC. It applies to maybe a few dozen people on earth. When a strong but normal candidate cites a headline they read, the move is not to match it, which you cannot, but to reframe: those numbers are lottery outcomes for a tiny cohort, the real market for their specific tribe and level is X, and here is everything beyond cash that you offer. The labs themselves know cash is not the whole game, which is precisely why the next sections on geography, motivation, and retention matter more than the bidding.
5. Where They Actually Live
Geography is destiny in AI hiring, and the concentration is more extreme than almost any other profession, which makes "where" one of the highest-leverage decisions you make. The San Francisco Bay Area is not merely the largest cluster, it is a structural gravity well: CBRE counted 76,079 AI tech-talent workers there, up 24% in a single year, more than New York and Seattle combined - CBRE. Three metros, the Bay Area, New York, and Seattle, hold about 35% of the entire US AI-specialty talent pool. The chart below shows the North American distribution, and the shape of it should inform whether you plan to compete in the densest, most expensive, most poach-prone market on earth or deliberately route around it.
AI Tech-Talent Workers by North American Metro (2025)
The reason the Bay Area dominates talent is that it dominates capital, and the two reinforce each other in a loop that is hard to break. San Francisco alone captured about $126 billion, fully 60% of global AI venture funding in 2025, and a staggering 81% of all Bay Area startup capital went to AI - The AI Economy. Money at that density funds the salaries, the compute, and the density of interesting problems that pull talent in and keep it there. For a recruiter, this cuts two ways. If you can hire in the Bay Area you have the deepest pool, but you also face the most aggressive competition and the highest prices. If you cannot, the strategic play is to fish where density is high but poaching is lighter, which increasingly means Toronto, which ranks third in North America with nearly 24,000 AI workers, or the fast-rising Indian hubs where AI hiring grew almost 60% year-over-year with Bangalore alone holding 40% of listings - The Hans India.
The frontier-research layer adds a wrinkle that surprises people used to remote-first software hiring: the top labs are aggressively office-first, which concentrates the scarcest talent even more tightly. OpenAI lists only about 4% of its roles as remote, the lowest among its peers, with an in-office expectation and a CEO who called remote work "a mistake," while Anthropic sits near 8%, concentrated in San Francisco, New York, and London - Jobs by Culture. This matters because it tells you that for the elite tier, you are not just competing on comp, you are competing on willingness to be physically present in a handful of zip codes. If your value proposition is remote flexibility, you are implicitly conceding the frontier-research tier and should aim your sourcing at the large and growing population of excellent engineers who actively want what the labs refuse to offer.
The global picture reframes the whole exercise, because the US talent base is not really American, it is imported, and that has become both its strength and its vulnerability. MacroPolo's Global AI Talent Tracker, the most-cited dataset here, finds the US employs about 59% of the world's elite AI researchers, but most of them were trained abroad, with 38% having done their undergraduate degree in China, now the single largest country of origin - MacroPolo. A separate analysis found roughly half the US AI workforce is foreign-born, and six of the eight authors of the original Transformer paper were immigrants - Institute for Progress. That dependence is now a live recruiting risk because of the September 2025 proclamation attaching a one-time $100,000 payment to many new H-1B petitions for beneficiaries outside the country - Bulletin of the Atomic Scientists. For a deeper breakdown of where skills concentrate worldwide, our global AI talent map covers the country-by-country density picture, but the recruiting implication is simple: visa strategy is now talent strategy, and the labs that can absorb a six-figure fee have an advantage over the startups that cannot, which is pushing sophisticated employers toward the uncapped O-1A "extraordinary ability" route that sits outside the new fee.
Knowing where the talent lives is only half the map, the other half is knowing who is pulling on it, because a handful of employers are scaling headcount fast enough to move the whole market. OpenAI reportedly plans to nearly double its workforce toward 8,000 people, Anthropic runs near 5,000 at a $380 billion valuation, and Nvidia alone grew to roughly 42,000 employees while paying its top AI engineers as much as $471,500 - Engadget. Underneath the giants sits a deep bench of well-funded upstarts recruiting almost purely on mission and founder pull, from Mira Murati's Thinking Machines Lab and Ilya Sutskever's Safe Superintelligence to Mistral in Paris and Fei-Fei Li's World Labs. For a recruiter at a normal company, this is the competitive weather: you are not only bidding against the lab that wants your candidate, you are bidding against everyone these giants are about to hire away from, which is why speed and a differentiated story matter far more than trying to out-price a market you cannot out-price.
6. Where to Find Them: The Signals That Predict Ability
The reason most AI sourcing fails is that recruiters search for titles and keywords when this population is uniquely legible through proof of work, and the proof lives in a handful of specific places. The single highest-signal channel is authorship at the top research venues, because acceptance there is brutally selective and unfakeable. NeurIPS 2025 drew roughly 29,000 attendees and accepted only about a quarter of more than 21,000 submissions, so a paper there, and especially an oral or spotlight, is a rarity signal no resume keyword can match - IntuitionLabs. The same logic applies to ICML, ICLR, and CVPR. For the research and applied-science tribes, the author lists of these conferences are quite literally the map of where elite talent sits, which is why MacroPolo builds its entire talent tracker from exactly these venues.
For the engineering tribes, the signals shift from papers to artifacts, and reading them correctly is what separates a good technical sourcer from a keyword-matcher. The most defensible practitioner signal is a Kaggle Competition Grandmaster rank, held by only about 362 people worldwide because it requires five gold medals including one won solo, which is why companies like NVIDIA and Airbnb actively recruit on it - Kaggle. On Hugging Face, which surpassed 13 million users, the meaningful signal is not how many models someone has posted but whether they authored a widely-used one, since the top 0.01% of models account for nearly half of all downloads - Hugging Face. GitHub commit history, read for what someone actually shipped rather than for stars, remains the best evidence that a candidate builds rather than merely talks, and our guide on finding data science talent on Kaggle goes deeper on reading competition signal specifically.
These signals are not interchangeable, and the practical art is matching the channel to the tribe you identified in section two. A few high-yield mappings are worth stating directly before explaining how to weigh them.
- Research scientists surface through NeurIPS, ICML, and ICLR authorship, citation counts on Google Scholar, and arXiv preprint activity.
- ML and research engineers reveal themselves through GitHub contributions to serious infrastructure repos, Kaggle medals, and Hugging Face model authorship.
- AI engineers are best read through shipped products, public repositories containing evaluation traces and cost dashboards, and contributions to popular open-source tooling.
- Applied scientists sit in between, with both a paper trail and a production code trail, so look for the rare profile that has both.
- Self-taught frontier talent clusters in open research communities like the Discord-born nonprofit EleutherAI, where many contributors have no PhD at all.
The reason this matters in practice is that sourcing on proof of work rather than pedigree dramatically widens and sharpens the funnel at the same time. Screening on demonstrated publications and repositories instead of titles has been reported to cut initial screening time substantially, because the signal is denser and harder to fake than a resume - Saral AI. It also rescues you from the pedigree trap, the tendency to over-index on a brand-name employer or a top-five PhD. Some of the most capable engineers in this field are self-taught people who shipped a notable open-source model or placed in a hard Kaggle competition, and they are systematically invisible to a recruiter searching for "Senior Data Scientist" at known companies. The conference circuit is also a live sourcing channel in person, and the gathering that has become the center of gravity for the AI engineer tribe specifically is worth watching closely.
AI Engineer World's Fair 2025 - Day 1 Keynotes and MCP track
The growth of that event is itself a sourcing data point. The AI Engineer conference series went from about 500 engineers at its first summit in late 2023 to thousands across many tracks, with a 2026 edition scaling further still - AI Engineer. For a recruiter, conferences are not just where you place a booth, they are where you identify the specific people giving talks, asking sharp questions, and maintaining the repos everyone depends on, then reach them directly afterward. The throughline of this entire section is that the best AI/ML talent leaves a public trail of competence, and the recruiters who win are the ones who learn to read that trail instead of waiting for the trail's owner to apply, which they rarely will.
One practical caution is that these signals are not all equally selective, and treating them as interchangeable badges leads to lazy screening. An ICML oral represents roughly the top one percent of an already-selective venue, a CVPR acceptance among many thousands of attendees is meaningful but more common, and a long list of arXiv preprints with no peer review behind them is weak evidence on its own - RIKEN AIP. The infrastructure that maps these signals also keeps shifting, so a sourcer has to stay current: when Meta retired Papers with Code in 2025, the canonical leaderboard-to-code trail that recruiters had leaned on for years moved to Hugging Face's paper pages, and a team still searching the old source was effectively blind. The deeper lesson is to weight the rarest, hardest-to-fake signals most heavily, and to keep checking which platforms even hold them, because the map of where competence is legible changes almost as fast as the field itself.
7. What Makes Them Move, and What Makes Them Stay
The most counterintuitive fact in this market, and the one most likely to save you money, is that for the people you most want, compensation is frequently not the deciding factor, and treating it as one will lose you candidates that more thoughtful competitors win. The clearest evidence is a one-sided flow of talent that money cannot explain. SignalFire's analysis found engineers were roughly eight times more likely to leave OpenAI for Anthropic than the reverse, and about eleven times more likely leaving DeepMind, even though all three pay at the very top of the market - SignalFire. People are not moving toward the biggest paycheck, they are moving toward something else, and identifying that something else is the core of a retention strategy that does not bankrupt you.
The first lever, and the one most under-appreciated outside the labs, is compute. Access to GPUs has become a literal recruiting currency, sometimes valued above cash and title. Zuckerberg said the thing top researchers tell him is "I want the fewest number of people reporting to me and the most GPUs," and framed compute-per-researcher as a tool for "attracting the best people," not just doing the work - WinBuzzer. Perplexity's CEO told a sharper version: a researcher he tried to recruit replied "come back to me when you have 10,000 H100 GPUs." For most companies this is humbling, because they cannot match a frontier lab's compute. But the principle generalizes downward: the second-order version of "most GPUs" is "real resources and real autonomy to do interesting work," and a smaller company that offers genuine ownership of a meaningful problem can beat a giant that offers a bigger number but a smaller sandbox.
The second lever is mission and research culture, which sounds soft until you watch it move nine-figure talent. The retention chart below shows the gap, and the lab that leads it does so on culture rather than on the biggest paychecks.
Two-Year Employee Retention at the Frontier Labs
Anthropic's retention edge, the highest among the labs, is attributed to researcher autonomy, the absence of title politics and forced management tracks, and an institutionalized transparency of company-wide AMAs and postmortems, which together produce an 88% engineering offer-acceptance rate - SignalFire. The proof that mission beats money outright keeps arriving in the form of refusals and defections that no compensation model predicts. One founder claimed an AI hire turned down $1.25 billion over four years - Tom's Hardware. Eight people quit Meta's Superintelligence Lab within two months of its launch, and Meta's chief AI scientist Yann LeCun departed after being asked to report to a much younger executive. Most tellingly, Andrej Karpathy chose to join Anthropic's pretraining team in 2026 specifically to get back to frontier research, prioritizing the work over his own venture - The Decoder.
None of this means compensation is irrelevant, and the labs have not stopped using it, they have just learned to use it as a retention floor rather than an attraction ceiling. OpenAI, under poaching pressure, eliminated its equity vesting cliff entirely, moving from a twelve-month standard to six months to zero, and projected roughly $6 billion in stock-based compensation, all explicitly to keep people from defecting - Fortune. The synthesis for a recruiter is a hierarchy of levers: pay a fair, competitive number to get into the conversation, then win on the things money cannot easily buy, namely meaningful problems, real resources, autonomy, a mission the candidate believes in, and colleagues they respect. The broader strategic version of this argument, applied across the whole talent war rather than just the frontier, is laid out in our guide on how to win the AI talent war, and its central finding is the same: the companies that compete only on cash lose to the companies that compete on cash plus story.
The mechanics of how the labs actually hold people are worth copying in spirit even if you cannot match the scale. Beyond base and equity, the frontier players use recurring liquidity as a retention tool, running large employee share sales that let staff cash out periodically and turning paper wealth into a reason to stay rather than a reason to leave - Fortune. The principle generalizes downward: retention is engineered, not hoped for, and the levers are predictable, namely a fair and legible comp structure, a path to liquidity or ownership, autonomy that grows with tenure, and a steady supply of work the person finds genuinely interesting. The companies that lose their best AI people almost always lose them not to a bigger number but to boredom, a reorg that buried their work, or a manager who treated a researcher like a ticket-closer, all of which sit within an employer's control and are far cheaper to fix than a bidding war.
8. How to Screen Them Without Getting Fooled
Screening AI/ML talent in 2026 is harder than it has ever been, for two reasons that pull in opposite directions: the old tests no longer measure the right things, and candidates can now use AI to pass the old tests anyway. Getting this wrong is expensive in both directions, because a false positive on a $245,000 engineer, let alone a frontier hire, is one of the costliest mistakes a team can make, while a false negative sends a genuinely strong builder to a competitor. The single biggest shift is the collapse of the generic algorithm puzzle as a useful filter. AI can now solve most easy and medium LeetCode problems in seconds, over 60% of candidates say such questions do not reflect their real work, and companies like Snapchat have removed them entirely in favor of practical screens - Feenyx.
What replaces the puzzle depends entirely on the tribe, and using the wrong replacement is its own failure mode. For machine learning and research engineers, the strongest signal is machine learning system design, the ability to reason end to end from problem framing through data pipeline, features, model architecture, training, evaluation, and deployment, with the maxim that "evaluation methodology is the new system design" - Exponent. The frontier labs screen each tribe differently and you should copy the logic: OpenAI runs a heavily coding-focused multi-hour onsite, Anthropic gates engineers on a CodeSignal test requiring essentially perfect correctness, and Google DeepMind, with sub-1% engineering acceptance, uses a rapid-fire fundamentals quiz - Sundeep Teki. For the AI engineer tribe, the most predictive screen is a live build against a realistic brief, which is why Anthropic's applied loop includes a multi-hour exercise building a Claude-powered app plus a customer-conversation simulation that filters most candidates who passed the coding stages.
It is worth seeing how concrete the best of these screens get, because the specificity is the point. Anthropic's engineering loop has reportedly asked candidates to implement multi-head attention with a key-value cache and grouped-query attention from scratch in about an hour, a task that is nearly impossible to bluff and that directly mirrors the real work - Perspective AI. The labs are also formalizing this into benchmarks you can borrow from, such as OpenAI's MLE-Bench, which scores agents against 75 real Kaggle machine learning engineering competitions on the actual medal system. The transferable idea for any team is to stop testing abstract puzzle-solving and start testing the candidate against a compressed version of the job itself, observed live, because a realistic task done under watch is the one thing an interview-day assistant cannot quietly complete on their behalf.
The harder, newer problem is that the assessment layer itself is under attack from AI-assisted cheating, and ignoring it is no longer an option. The scale is genuinely alarming.
- A study of 19,368 interviews found 38.5% of all candidates flagged for cheating, rising to 48% for technical roles - Fabric.
- Of detected cheating, 45% used dedicated assistants like Cluely or Interview Coder, and 61% of cheaters scored above pass thresholds.
- A three-hour take-home that AI now completes in about eight minutes has effectively died as a screen.
- Cluely, the "cheat on everything" startup, raised $15 million from a top venture firm at a roughly $120 million valuation.
- In response, Google, Cisco, and McKinsey have reinstated in-person interviews, and a Gartner survey found 72.4% of recruiting leaders now interview in person.
The practical defense is a deliberate redesign of the screen around things AI assistance cannot easily fake, and this is where most teams are still behind. The take-home is dead as a standalone filter, so either move it into a live, observed setting or pair it with a synchronous follow-up where the candidate must explain and extend their own submission under questioning. Lean on the unfakeable proof-of-work signals from section six, a real Kaggle rank or an authored Hugging Face model or a substantive GitHub history, as a credential that no interview-day tool can manufacture in the moment. And for the highest-stakes roles, accept what the labs have already concluded: a final onsite, in person, watching the candidate think and build, is worth the logistical cost because the downside of a confident fraud at this pay level is catastrophic. The goal of screening has quietly shifted from testing whether someone can produce an answer, which AI now trivializes, to verifying that a specific human actually possesses the judgment the answer implies, which is exactly what the cheap, automated end of assessment can no longer guarantee.
9. The Sourcing Playbook and the Tool Stack
Pulling the previous sections together into an operating playbook starts with a single decision that determines everything else: which tribe you need, which dictates the channel, the tool, and the message. The most common and most expensive failure is to run one generic sourcing motion across all five tribes, blasting the same LinkedIn template at a research scientist and an AI engineer and converting neither. The diagram below maps the major needs to the channels that actually fit them, and it is worth using as a first cut before you open a single tool or write a single message.
The outreach itself has to clear a high bar because this audience is the most heavily solicited talent on earth and has a finely tuned filter for recruiter spam. A generic "exciting opportunity at a fast-growing startup" message to someone who authored a cited paper or maintains a popular repository is not just ignored, it is mildly insulting, because it signals you did not read their work. The motion that converts is specific and earned: reference the actual paper, repo, or competition result, demonstrate that you understand what is hard about their work, and lead with the parts of your offer that map to section seven, the problem, the resources, the autonomy, and the team, rather than opening with comp. This is slower per message and dramatically higher converting, and it is the opposite of the high-volume, low-personalization motion that works for more abundant roles.
The tool market has organized itself around making this motion scalable, and the categories matter more than any individual brand. At the sourcing layer, natural-language search tools like Juicebox, which searches across hundreds of millions of profiles, list pricing around $139 to $199 a month with an autonomous outreach agent add-on, while platforms aimed at in-house teams such as hireEZ and SeekOut sit in the $149 to $250-per-user range - Juicebox. For deep technical sourcing specifically, AmazingHiring unifies GitHub, Stack Overflow, and Kaggle into single profiles at roughly $3,600 to $4,800 per user a year, and LinkedIn Recruiter remains the expensive default at up to nearly $13,000 per seat. At the assessment layer, HackerRank and CodeSignal handle technical screening, with CodeSignal moving to quote-based pricing around $19,000 a year and adding agentic assessment generation for machine learning and data-science roles. The interpretive point is that no single tool covers all five tribes, and the right stack is usually a sourcing tool plus a technical-signal tool plus an assessment tool, chosen for the tribe you hire most.
The newest and fastest-moving category is the autonomous AI recruiter, which compresses sourcing, qualification, and first-touch outreach into a single agent, and it is reshaping how lean teams compete for this talent. LinkedIn shipped its first recruiting agent, Hiring Assistant, which early adopters credited with reviewing 62% fewer profiles while improving response acceptance - LinkedIn, and venture money has poured into the category. This is the part of the market where a tool like HeroHunt.ai fits as one option among several: its AI Recruiter runs autonomous sourcing and personalized outreach across more than a billion public profiles, which is useful precisely because the credentialed specialists you want, the research scientists and senior ML engineers, overwhelmingly never register on any annotation platform or apply to any posting, so reaching them means going to where they already are. For a buyer choosing among these autonomous tools, the relevant questions are profile coverage, the quality of the personalization, and whether the agent can read the proof-of-work signals that actually predict ability, and you can start for free on most of them to compare. The boutique alternative, specialist AI/ML headhunting firms that charge 15 to 25% of first-year salary, makes sense only for the rarest searches where a managed, deeply vetted process justifies the premium.
One hard-won lesson from the talent war belongs in any sourcing playbook, and it is about who you let near your hiring and your data. When Meta took its stake in a major data vendor, several of that vendor's biggest customers, including Google and OpenAI, moved to cut ties rather than route their work through a partner now aligned with a competitor - CNBC. The generalized version for recruiting is to screen your vendors and channels for conflicts of interest before you commit, because feeding your hiring pipeline, your candidate data, or your roadmap through a tool or agency entangled with a rival is now understood as a strategic risk rather than a hypothetical one. The build-versus-buy decision, in the end, turns on durability: a one-off search can go to an agency or a self-serve tool, but a standing need to hire scarce specialists is worth building into an owned capability, because the relationships and the proprietary pipeline compound in a way a transactional vendor never will.
10. The Insider Reality Nobody Advertises
Every recruiting page in this market sells the same clean story of abundant demand and limitless comp, and the reality underneath is messier, more bimodal, and more contingent than any of it admits. Seeing it clearly is what separates a recruiter who makes good decisions from one who chases headlines into expensive mistakes. The first uncomfortable truth is the one the comp section hinted at: the AI premium is real but it is concentrated and unstable, not a smooth rising tide. The image below shows how sharply the premium varies, with AI engineers out-earning their non-AI peers at nearly every company and the gap widening at the most senior levels.

That premium sits on top of a job market that is openly two-speed, and conflating the two speeds is how companies misread their own leverage. While AI and machine learning roles boomed, the broader tech market shed jobs, much of it explicitly attributed to AI: Amazon announced 14,000 corporate cuts with its CEO citing AI agents, and Salesforce cut support headcount from 9,000 to about 5,000 - CBS News. The most consequential version of this for AI hiring specifically is the collapse of the entry level. Stanford's Digital Economy Lab found a 16% relative employment decline for workers aged 22 to 25 in AI-exposed jobs like software engineering, even as employment for older workers in the same roles held or grew - Stanford Digital Economy Lab. Entry-level developer postings fell roughly 60% over two years, and a striking share of managers say they would rather use AI than hire a recent graduate. The market is compressing into a senior-led core, which is great for senior candidates and quietly building a future leadership vacuum nobody is hiring to prevent.
The talent war at the top is also far less stable than its valuations suggest, and the churn is a warning to anyone tempted to buy talent purely with money. The wave of reverse-acquihires, where a giant licenses a startup's technology and hires its founders without a formal acquisition, has concentrated elite talent through deals like Inflection into Microsoft, Character.AI into Google, and Adept into Amazon, with the structure drawing antitrust scrutiny and leaving "zombie" startups behind - Fortune. The most expensive talent grab of all, Meta's $14.3 billion for a non-voting minority of Scale AI to bring in its founder, sits at the center of this story, and the person it installed has become the face of the entire war.

The instability is the lesson, not the spectacle. Within months of assembling its expensive new lab, Meta cut roughly 600 roles from its broader AI division, and several of the marquee hires the war was fought over had already left or returned to their old employers, with one high-profile new lab losing four of its five co-founders inside a year. For a recruiter, the takeaway is bracing and useful: money buys a signature, not loyalty, and a hire made purely on a number is a hire your competitor can unmake with a bigger number or, more often, a better mission.
The poaching also carries a darker, legal edge that belongs in any honest account, because when people move this fast and this expensively, disputes follow them. xAI sued one of its first twenty engineers in 2025, alleging he downloaded its entire model codebase after cashing out millions in equity, and then accused a rival of an unlawful campaign to poach its staff - San Francisco Standard. For a recruiter, the lesson is not to avoid hiring from competitors, which is normal and legal, but to be scrupulous about it: state in writing that you do not want a candidate's former-employer code or trade secrets, document it, and treat anyone who volunteers to bring proprietary material as a liability rather than an asset. In a market where a single senior hire can carry enormous institutional knowledge in their head, the line between legitimate talent movement and actionable theft is one both sides now litigate aggressively. The final insider truth is that this entire market is moving too fast for any static playbook, with skills in the most AI-exposed roles changing dramatically faster than elsewhere and a 56% wage premium on AI skills that doubled in a single year - PwC. The half-life of a hot skill is now short enough that you are really hiring for learning velocity, not for a snapshot of current knowledge, which is a different and harder thing to screen for than most job descriptions admit.
11. The Future: When AI Agents Recruit and Build AI Engineers
The question hanging over this entire market is whether the people building AI will be replaced by it, on both sides of the hiring table, and the honest 2026 answer is that the work is being reshaped rather than eliminated, with the value migrating up the skill ladder on both sides. On the recruiting side, autonomous agents are arriving fast: Korn Ferry found 52% of talent leaders plan to add autonomous AI agents to their teams in 2026, with 84% planning to use AI overall - Korn Ferry. The sourcing and first-touch layers of recruiting, the parts that are high-volume and pattern-driven, are exactly where these agents are most capable, which is why the autonomous-recruiter category from section nine is growing so quickly.
The sober counterweight is that the same research shows AI has not displaced human judgment in hiring, and the recruiters who assume it will are getting ahead of the evidence. Korn Ferry found that even as adoption surges, 73% of recruiters rank critical thinking as their top priority when evaluating candidates, with AI skills only fifth, and Gartner expects more than 40% of agentic AI projects to be canceled by 2027 amid limited demonstrated value so far - Pin. The realistic near-term picture is augmentation: agents handle the sourcing grind and the scheduling and the first qualifying pass, while humans own the judgment-heavy work of assessing a borderline candidate, selling the mission, and closing. The recruiter whose value was purely volume sourcing is genuinely threatened. The recruiter whose value is judgment and relationship is more valuable, because the volume layer that used to consume their time is now cheap.
The mirror-image question, whether AI engineers themselves get automated, has the most nuanced answer and it directly shapes who you should be hiring. The capability is advancing strikingly fast: METR found that Claude Opus 4.5 could complete tasks with a 50% success rate up to a roughly five-hour time horizon, with that horizon doubling about every three months - METR. Karpathy named December 2025 as the moment agentic coding became reliable enough that he stopped correcting it, and Anthropic's leadership has claimed AI now writes the overwhelming majority of its code. Yet on longer-horizon research-engineering tasks, the same benchmarks show humans still decisively ahead at the 8-hour and 32-hour marks, so the work that is being automated is the bounded, well-specified piece, not the open-ended judgment that defines senior AI work.
A second force is quietly reshaping who hires these people directly, and it favors candidates who can sit close to the work. The frontier labs are increasingly insourcing the talent they used to rent, hiring experts straight onto internal teams and pushing deployment engineers in front of customers through the Forward-Deployed Engineer model rather than routing everything through vendors. That insourcing trend means more of the best roles will be direct hires at the labs and their largest customers, which raises the bar for everyone else but also opens a gap: the engineers who want autonomy, a clear mission, or simply a smaller pond will keep choosing companies that are not the giants, and a thoughtful recruiter who offers exactly those things can win people the labs would otherwise absorb. The future of this role is not human or machine, it is humans who direct machines, and the recruiting contest is increasingly about who can offer that kind of work in an environment a person actually wants to spend their years inside.
What this does is bifurcate the role you are hiring for, hardening exactly the pattern the rest of this guide described. The bounded, junior, well-specified end of AI/ML engineering is being absorbed by agents fastest, which is the mechanical reason entry-level hiring collapsed and why the market rewards senior judgment so heavily. The open-ended end, framing the right problem, designing the evaluation, architecting the system, and verifying that an agent's output is actually correct, is growing more valuable, not less, which is why the WEF still projects AI and machine learning specialist roles to grow about 82% by 2030 - World Economic Forum. The recruiting implication is unambiguous and it is where this guide has been pointing all along: hire for the capabilities AI is not absorbing, namely judgment, taste, system-level thinking, and the ability to direct and verify increasingly autonomous tools, because those are the skills that are appreciating while the skills you can automate quietly depreciate.
Conclusion: How to Act on This
Recruiting the modern data scientist in 2026 comes down to refusing to treat the role as one thing, because it is at least five things with five different channels, five different screens, and pay that spans an order of magnitude. Almost every costly mistake on either side of the table, the seven-figure offer to someone who wanted a research agenda, the LeetCode round that screened out a brilliant builder, the generic message that an authored researcher deleted on sight, traces back to confusing one tribe for another. The single discipline that protects you is to name precisely which tribe you need before you do anything else, then match the channel, the signal, the screen, and the pitch to that specific person.
If you are sourcing this talent, lead with proof of work rather than titles, because this is the rare population that leaves a public, unfakeable trail of competence in papers, repositories, models, and competition ranks. Compete on cash to enter the conversation, then win on the things money cannot easily buy, the problem, the compute and resources, the autonomy, the mission, and the colleagues, because the one-sided talent flows prove those levers move people that bigger numbers cannot. Redesign your screens around what AI assistance cannot fake, lean on real-world artifacts and live, observed assessment, and accept that for the highest-stakes hires the in-person onsite has come back for good reason. And use the new autonomous tooling for the volume layers while keeping your own judgment on the parts that decide whether a hire works.
The deeper point is that the people who build AI have become one of the most valuable and least understood labor forces in technology, and the confusion around them is not an accident, it is the product of a market moving faster than its own vocabulary. The job title says "data scientist," the reality is five evolving species, and the comp headlines describe a stratosphere that almost no actual hire lives in. Seeing the system clearly, which tribe you need, what they actually earn, where they leave their trail, and what genuinely moves them, is the entire advantage. Use it before the next reorganization of this market makes today's map obsolete, which, at the current pace, will not take long.
This guide reflects the AI and machine learning talent market as of June 2026. Compensation figures, platform pricing, headcounts, visa rules, and the legal status of the deals described here change constantly, so verify current details before making a hiring or career decision based on them.



